REF_WEEK_03
The workshop began with a bit of digital housekeeping. We spent the initial moments troubleshooting web hosting issues to ensure everyone could smoothly upload their portfolios via FTP. It felt like a necessary rite of passage—setting up our own "home" on the web before venturing out to scrape others'. However, it didn’t take long to pivot to the core task: Web Scraping. Having read the literature and watched the tutorials beforehand, I understood why we were doing this. As digital researchers, we cannot simply rely on what platforms want to show us; we need tools to extract the data systematically. It was time to put theory into practice.
Our first mission was to scrape a video platform. I chose the BBC iPlayer, focusing on their "Most Popular" section.
 Figure 1.0: The first version of scraping BBC.
Figure 1.0: The first version of scraping BBC.
While the in-class exercise was great, I wanted to push the boundaries. With a little help from Python scripts, I managed to extract not just the titles, but richer metadata including duration and synopses (descriptions). Looking at this spreadsheet of data, I realized these columns were more than just text; they were sociological evidence.
The Language of Promotion: By analyzing the vocabulary BBC uses in descriptions (e.g., words like "shocking," "exclusive"), we can understand what the platform believes "sells" to the audience. It’s a glimpse into their framing strategies.
The Economy of Attention: Analyzing the duration of the top 10 videos offers insight into the modern attention span. Are 50-minute dramas winning, or are we shifting toward shorter, snappier content?
This process allowed me to witness datafication in action—breaking down fluid cultural content into sortable, analyzable units.
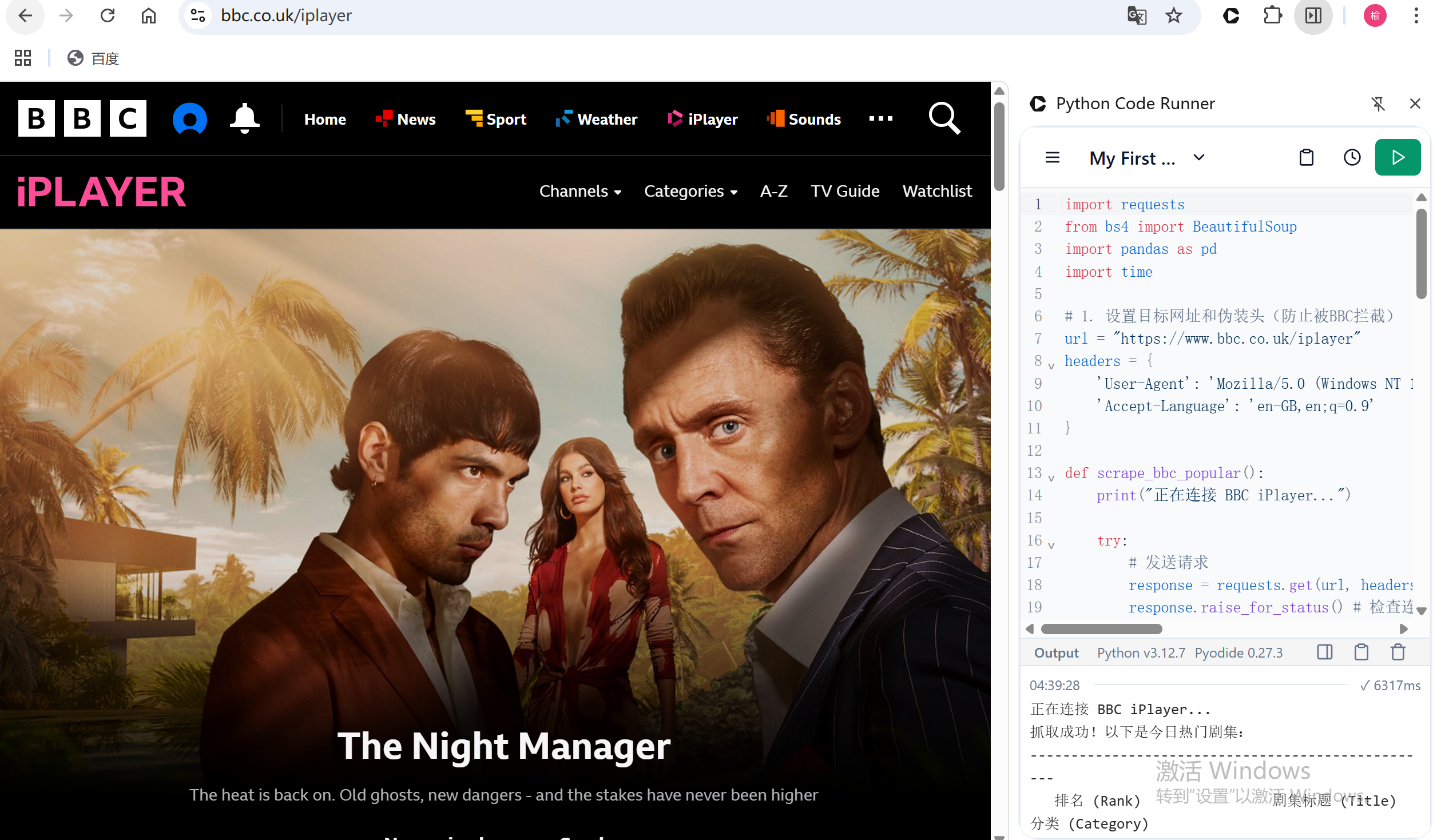
 Figure 2.0: The iterative process of data extraction and the refined dataset.
Figure 2.0: The iterative process of data extraction and the refined dataset.
The most striking moment, however, came when we looked beyond the visible interface and into the source code. On the surface, the homepage is clean and user-friendly. But in the code, I found mechanisms designed to watch us while we watch them. Specifically, I uncovered two unsettling pieces of code. test_aa_mparticle_age suggests the platform is actively testing ways to profile users based on age, feeding algorithms that desperately want to categorize my generation. Another key, challenger-page-landed, reveals the platform's anxiety about user retention, monitoring exactly how many people "bounce" when forced to sign in.
Seeing these tracking codes made the theoretical readings terrifyingly real. These lines of code are silently observing, recording, and analyzing our behavior. It reminded me of Tiidenberg & van der Nagel's argument that on digital platforms, complete anonymity is essentially impossible. No matter how much we try to hide our footprints, the architecture is designed to capture us. When this data is collected across platforms, it leads to profiling, context collapse, and vulnerability. This workshop was a revelation. I started by learning how to host a website, but I ended up learning how to deconstruct one. By scraping the BBC, I didn't just get a list of TV shows; I got a glimpse into the power structure of the platform. We are not just users; to the code, we are data points waiting to be harvested.